| 白小交 西小风 发自 各自家里 自从Ilya Sutskever的名字出现在OpenAI o1背后团队名单中,他在o1中发挥了哪些作用,一时间成为不少网友的关注焦点。 
这不,机器学习工程师Rohan Paul刚刚发帖表示,去年5月份Ilya合著的一篇论文不能错过。 论文题为“Let’s Verify Step by Step(一步步来验证)”。 不光是Ilya,其中还有不少作者同样是OpenAI o1的背后贡献者。 
甚至有网友将这篇论文称作是AI领域仅次于“Attention is all you need”的第二著名论文。 
除此之外,在关于OpenAI o1背后团队的热议中,OpenAI科学家Noam Brown最近发帖澄清并没有主导草莓/OpenAI o1。 但同时也透露o1项目是一个多年研究的成果,从去年10月开始真正加速发展。 
这么来看,Ilya Sutskever会是OpenAI o1的“基础贡献者”也就更不令人意外了。 接下来深入看看“Let’s Verify Step by Step”这篇论文以及OpenAI o1背后的贡献者。 Ilya在o1的作用 OpenAI o1主打进行通用复杂推理,在输出回答之前,会在产生一个很长的思维链,以此增强模型能力。 而Ilya此前合著的这篇论文主要就是探讨了提高大语言模型多步推理能力的方法。 他们主要比较了结果监督(outcome supervision)和过程监督(process supervision)两种方法在训练奖励模型上的效果。 结果监督侧重于模型最终输出的正确性。 而过程监督则关注模型在推理过程中每一步的正确性,能够指出答案中具体哪一步是错的: 
团队使用GPT-4基础模型,在MATH数据集上进行了实验。 由于过程监督没有简单的自动化方法,所以只能依靠人工数据标注者来标记模型生成解决方案中每个步骤的正确性。 他们收集了大量人类反馈数据,创建了PRM800K数据集,包含80万个步级标签。 实验分为大规模和小规模两种体制,各有优势并提供不同视角。 研究结果发现:过程监督显著优于结果监督,能够训练出更可靠的奖励模型。 使用过程监督训练的最佳模型在MATH测试集具有代表性的子集上解决了78.2%的问题,明显优于结果监督模型(72.4%)和多数投票基线(69.6%)。 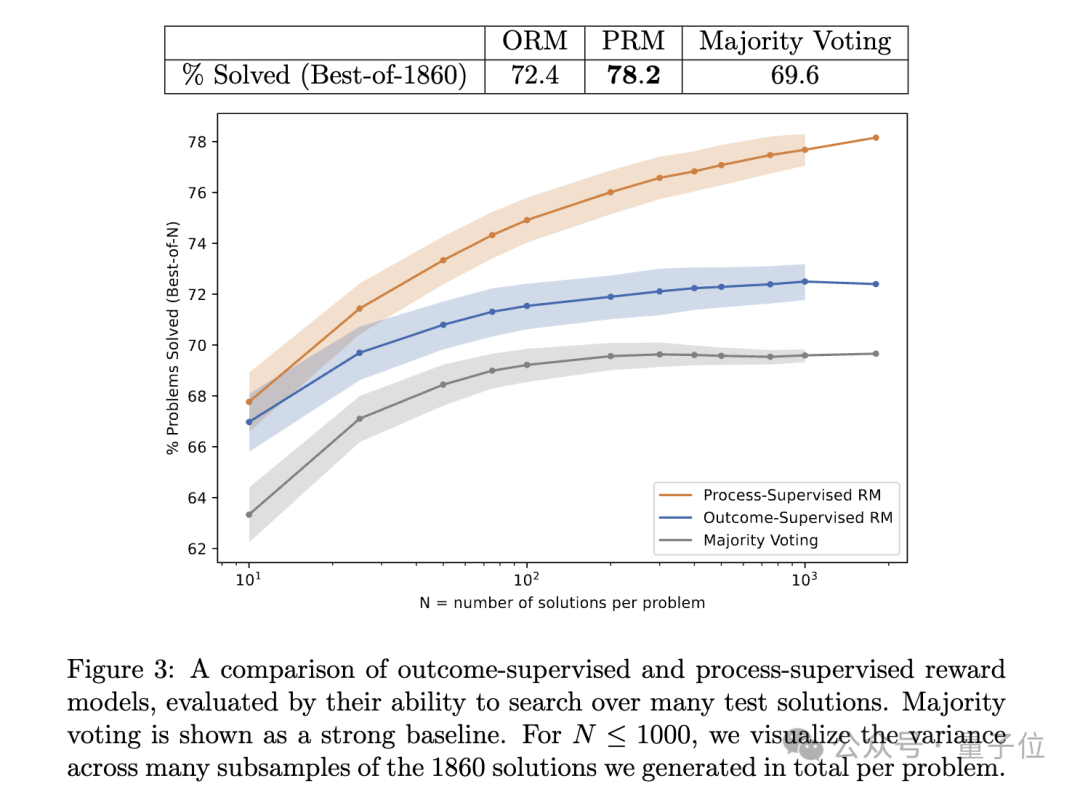
研究还证明了大型奖励模型能够可靠地近似人类监督对较小奖励模型的效果,并且能够高效地进行大规模数据收集的消融分析。 主动学习(active learning)还可以显著提高过程监督的数据效率,大约提升了2.6倍。 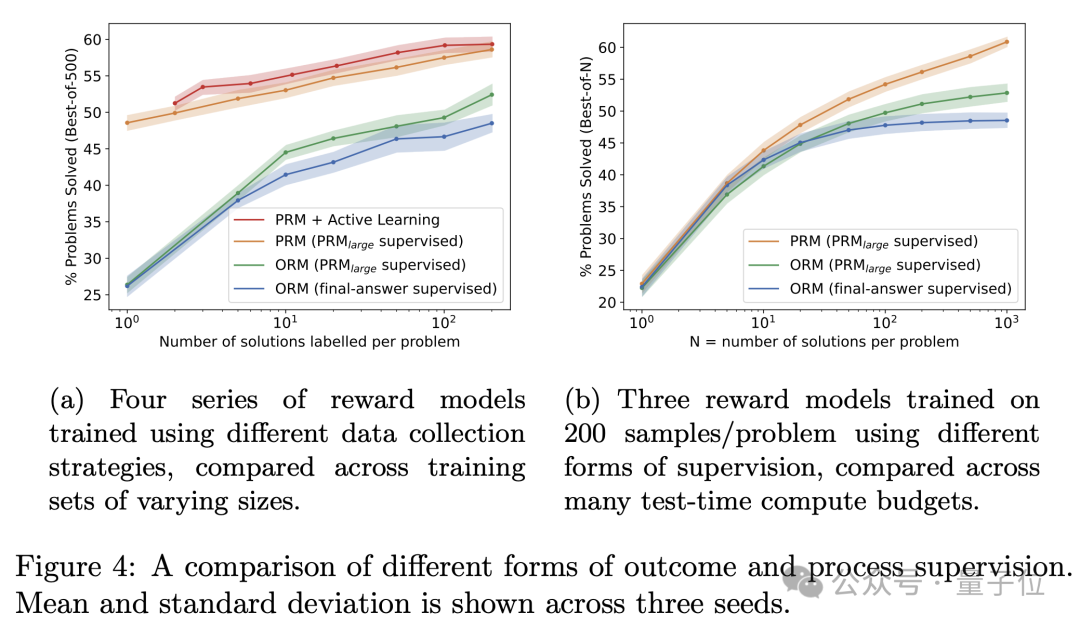
团队还讨论了过程监督的几个关键优势。 首先,它提供了更精确的反馈,使得功劳归因更加容易。其次,在AI对齐方面,过程监督更有可能产生可解释的推理。 为了评估模型的泛化能力,团队还在AP物理、AP微积分、AP化学和AMC考试题目上进行了测试。 结果显示,过程监督训练的模型在这些新问题上仍然表现优异,证明了其对适度分布偏移的鲁棒性。 大模型飞速发展一年后的今天,再来看这篇论文,有学者指出现在来看没有太多新的想法: 关键idea就是过程奖励模型,它可以单独评估每个步骤或token,而不仅是最终结果。 
但也正如网友所说,这篇论文总归来说是迈向OpenAI o1的一步。 
o1则代表了“从记忆答案到记忆推理的范式转变”。 
清北校友o1-mini主要负责人 除了Ilya Sutskever,关于o1背后团队也引发了不少关注。 官网给出的全名单,分成了推理研究和推理技术安全两块。粗略一看已经远远超一百人。(好多人啊,GIF) 
咱们主要看看研究这块。 基础贡献者:21人;Leadership:7人; 核心贡献者:46人; 贡献者:82人; 项目经理:2人; 执行领导:8人; 支持领导:8人。 在基础贡献者中我们也看到了不少熟悉的影子以及华人面孔。 
Jason Wei,OpenAI研究员,此前曾在谷歌大脑工作,他是思维链的提出者,也曾参与大模型涌现能力以及GPT-4的研究。 
Shengjia Zhao,本科毕业于清华,随后前往斯坦福攻读博士学位,22年毕业之后就来到OpenAI。个人介绍中显示,热衷于训练大模型,他是ChatGPT、GPT-4、GPT-4o mini的核心作者之一。 
任泓宇,2018年毕业于北京大学,随后来到斯坦福攻读计算机博士学位,当时方向就是大语言模型。加入OpenAI之前曾在微软英伟达谷歌苹果这些科技巨头待过。他是GPT-4o 的核心贡献者,GPT-4o mini 的领导者,主要教模型如何更快、更努力、更敏锐的思考。 
当模型第一时间发布时,他曾表示o1-mini是他最喜欢的一款模型。 
以上这两位清华北大校友,应该是o1-mini的主要负责人没跑了。 

Francis Song,本博分别毕业于耶鲁和哈佛,曾在NYU担任助理研究员,方向是计算神经科学。在DeepMind待了四年后,22年来到了OpenAI。 Wenda Zhou,本科毕业于剑桥大学,在哥伦比亚大学获得博士学位,来到OpenAI之前曾在Simons/NYU当研究院,去年加入OpenAI。 Kevin Yu,毕业于UC伯克利,曾就职于NASA。 在Leadership里还有位华人面孔。 Mark Chen,目前是OpenAI(前沿)研究副总裁。曾就读于MIT数学与计算机科学专业,曾在Integral Technology担任量化研究合伙人。 
最后,也附上全体名单。 
△ 推理研究 
△ 推理技术安全 奥特曼:已掌握未来几年主动权 话说回来,前两天奥特曼又去接受公开采访了,聊了聊最新的这个模型。 他表示o1模型虽然能在IOI、IMO这样的竞赛中取得优异成绩,但重点不应该放在AI擅长考试这一点上。而是它能帮助研究人员,比如更快发现新材料、找到治疗疾病的方法等等。 这是个新范式的开始,非常早期但非常重要。 谈到未来的愿景,他提到,未来将有两种基本商品,那就是是智慧和能源——拥有创意的能力,完成智力工作的能力,以及能源,即在世界上实现这些目标的能力。 至于大模型进展,他表示不仅没有放缓,而且已经掌握了未来几年的主动权。 
|
